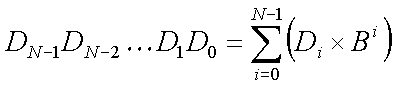
(Last Mod: 27 November 2010 21:38:43 )
Binary Representations Home Page
When you see the "number" 22 written on a piece of paper what you are really seeing is a symbolic representation that is intended to communicate an idea - namely the idea of the number twenty-two. Those two 2's sitting next to each other are not twenty-two of anything. Indeed, the very concept of "twenty-two" is an abstract one.
"So what?" you might ask. Indeed, most of the time there is no need to be so specific about the distinction - humans have an extremely well developed ability to take a symbolic representation and extract from it the concept that is being communicated. We do this automatically and it serves us very well, but it can get in our way when we need to focus on the representation itself separate from the concept that is being represented.
In this module we do precisely that. So we will first make sure that the representation we use in everyday life is very well defined and understood. Then we will see how we can use those concepts as the foundation for new ways of representing numbers - ways that a computer can deal with.
We will begin with how we represent positive integers as this is the most basic representation from which all others are built. We will then extend this to include negative numbers and then to fractional values. Finally we will extend it to include extremely large and extremely small values.
In most situations we use the Hindu/Arabic numbering system. Unlike an additive numbering system such as the Roman Numeral system, the Hindu/Arabic system is a positional numbering system. Like all but two of the widespread positional systems throughout history, it is a base-10 system. The Babylonians used a base-60 system - which we still have remnants of in our units for time and for angular measure. The Maya used a base-20 system and are thought to be the first culture to explicitly incorporate the concept of "zero" in representing numbers.
The basic idea behind a positional numbering system is to be able to represent a large range of quantities with a high degree of accuracy while using a relatively small number of characters. For instance, in our base-10 system, we can uniquely represent one million different values using only six characters. Another important feature is that the mechanics of performing arithmetic in a positional numbering system are straight forward and well-structured. Imagine having to describe how to multiply two values together that are written using Roman Numerals.
So what is needed to support a positional numbering system? In it's most basic form, all we need is selection of primitive symbols equal to the base. These symbols represent the integer values zero through one less than the base. These symbols are collectively referred to as the numbering system's "digits". Hence, in a base-10 system, we need ten symbols - or digits - that represent the integers zero through nine. Given these digits, we can then represent numbers using a string of these digits in such a way that the value being represented not only depends on the digit used, but on that digit's position within the string. Hence, 1667 is not the same as 7616 even though both strings use the same digits the same number of times. As we expand the range of concepts we can communicate with our numbering system we will see that we need just a few more symbols, namely a negative sign, a radix mark, and a means of indicating exponents. At the appropriate point, we will examine what those symbols are, what they mean, and how to use them.
As we shall see, the rules that we use to construct a string of digits that represent a number and, conversely, to interpret a string of digits to determine what number is being represented, are quite straightforward. Most readers of this material have learned and internalized these rules over the past decade or more. But what has really been internalized are practical ways of applying the rules when working with base-10 numbers - and as proficient as someone might be at this, they may not have a sufficient grasp of the rules themselves in order to apply them to non base-10 numbering systems or systems that otherwise differ from the ones we use everyday. So our first task is to explicitly develop a set of rules that describes our everyday use of a positional numbering system before we proceed to discuss how these rules are applied to computer-based representations.
The most important rules for working with positional numbering systems are most clearly seen when applied to one of the most basic type of numbers - the nonnegative integers (i.e., the set {0,1,2,3,...}). This set is frequently referred to as the set of "whole" numbers.
A formal way of expressing what the value represented by a string of N digits (in any positive integer base, B, where B has a value of two or greater) would be:
Here we have an N-digit number written in base B. The ith digit, Di, is one of the symbols representing the integer values {0..(B-1)}. The value Bi is the "weight" of the ith digit. Hence the value represented by a string of digits in a positional numbering system is the "weighted sum" of all the digits. The phrase "weighted sum" simply means that each digit is multiplied by an appropriate weighting factor before being summed.
As a matter of verbal shorthand, we will frequently hear phrases like, "The digit '2' has an exponent of three," when discussing a value such as 4238. Taken literally, this would say that we have 23. What we really mean is that the weight of the digit '2' is the number base raised to the exponent of three - or, in this example, that we have 2x103. But this is a lot of words that quickly get in our way and so we simply agree that when we talk about a "digit" within a number "having an exponent" what we are referring to is the exponent that the base is raised to prior to multiplying it by that digit.
Given a string of digits that represent a nonnegative integer, we can determine the value that is represented by applying the most fundamental property of a positional numbering system embodied by the formal description above - namely that the position of each digit provides information as to how much "weight" that digit carries in the final result.
By way of example, consider the following:
k = 4532 (B=10)
D0 = 2
D1 = 3
D2 = 5
D3 = 4
k = 4x103 + 5x102 + 3*101 + 2*100
k = 4x1000 + 5x100 + 3*10 + 2
k = 4000 + 500 + 30 + 2 = 4532
The above should not come as any surprise, nor should the corresponding results when B is something other than 10.
k = 45326
D0 = 2
D1 = 3
D2 = 5
D3 = 4
k = 4x63 + 5x62 + 3*61 + 2*60
k = 4x216 + 5x36 + 3*6 + 2
k = 864 + 180 + 18 + 2 = 1064
Note that in the last example, the base was indicated in the original number by a subscript following it. All of the rest of the numbers in the example were expressed in base ten. In fact, had we written all of the numbers throughout the example in the original base, the results would have been identical to the earlier results because any number base is written as " 10" in that number base. Note that this would include the number that represents the number base in the subscript itself. Hence you begin to see how tied we are to the decimal number system - even when writing a number in another base, we generally rely on the reader assuming that the base of the number is indicated in base ten. This is why some authors prefer to spell out the number base instead of representing it numerically, such as:
k = 4532six
When we write a number, we need to be sure that the number base used is clearly understood. In every day life we almost always work with decimal values (base-10) and hence don't worry about indicating this - it is simply understood by everyone as the assumed number base.
But when we work in other bases we need to be more careful. Sometimes the context of the discussion makes it clear what the number base in use is, but if there is any chance for miscommunication then we need to be more explicit. The most common way of indicating the number base used for a specific number is to follow it with a subscripted value, spelled out or written in base ten, indicating the base.
Sometimes this is inconvenient or even impossible since text files do not support the use of subscripts. In that case we need another way to represent the value.
For our use, we will either follow the value with a subscript indicating the base or, alternatively, use the following notations for the common bases we will be working with:
| Base | Name | Digits | Notation | Example of Representation |
| 2 | binary | 0,1 | Suffix with 'b' | 1110 1111b |
| 10 | decimal | 0...9 | (none) | 96 |
| 16 | hexadecimal | 0...9,A...F | Suffix with 'H' | 5FH |
| 16 | hexadecimal | 0...9,A...F | Prefix with '0x' | 0x5F |
Notice that there are two common alternate notations for hexadecimal. We will predominantly use the '0x' prefix because this is the notation used by the C programming language.
In the case of binary numbers, we will generally write the value in groups of four digits. The purpose is simply to make the value easier to read - the space has no impact on the value at all just as we commonly use commas to group a base ten number into groups of three digits.
When figuring out what value is represented by a string of numbers, we have the advantage of knowing what N is before we even start - we can count the the number of digits. When going the other way, determining what string of digits to use to represent a particular value, we generally don't have that piece of information. But it turns out that the steps needed to get it are not that difficult and that, like most problems, there is more than one viable solution.
First, let's take a mathematically rigorous approach. Consider the range of values that can be represented with an N-digit number, where we are assuming that the leading digit is something other than zero. The smallest value that can be represented is a 1 followed by (N-1) zeros. The largest value that can be represented is a string of N digits where each digit is the largest digit available. For B=10 and N=4, this would mean 1000 and 9999 respectively. Notice what happens if we add one to the upper limit. We end up with the first number that is too great to represent with an N-digit number and this number is easier to work with than the largest number that we can represent.
Using the above results, we can conclude that if k is an N-digit number that it must obey the following relationship:
B(N-1) <= k < BN
Note that this is actually two inequalities that just happen to be written in a single expression. In order for the expression to be true, both inequalities must simultaneously be true.
( B(N-1) <= k ) AND ( k < BN )
So, given a value k that we want to represent in a number base B, how many digits are required? We can work with either inequality and solve for N. For simplicity, we will use the right hand expression:
k < BN
ln(k) < N*ln(B)
N > ln(k)/ln(B)
Note that we could have taken the logarithms to any number base, as long as we were consistent. You should verify that you get the same result if you use common logs (i.e., base ten logs) as when you use natural logs.
Since N is an integer and it is strictly greater than the ratio on the right, all we must do is compute the right hand side and round it up to the next integer, even if it comes out to be an integer since, in that case, we must still add one to get a value for N that is strictly greater than the right hand side. Although technically we could use any value of N that is greater than the right hand side, doing so would violate the first inequality above except for the single value of N obtained by rounding up to the next integer.
Just as ln() is a simple notation that tells us to compute one value based upon another, we can create other functions that behave similarly to make our notation simpler. Two such functions are floor() and ceil(). The floor() function tells us to compute the largest integer that is not larger than the argument while the ceil() function tells us to compute the smallest integer that is not smaller than the argument.
So which do we want to use here? It would be tempting to use the ceil() function since, on the surface, it appears to "round up" which is what we want to do. But we have to consider the behavior in those cases where the argument is an integer. If ln(k)/ln(B) turns out to be exactly 4, for instance, we need five digits. However, while the ceil() function would evaluate to 5 if the ratio came out to be 4.1, it would evaluate to 4 in the case above because that is the smallest integer that is not smaller than 4.
What would happen if we used the floor() function? In the case that ln(k)/ln(B) came out to be exactly 4, then it would still evaluate to 4. But it would also evaluate to 4 in the case where the ratio turned out to be 4.1 or 4.9. Hence it would always turn out to be one too small. But this is easily handled. If the result is always one too small, simply always add one to the result.
Hence we have:
N = floor( ( ln(k) / ln(B) ) + 1 )
You should be able derive the same result using the first inequality.
Once we know how many digits are in the number, we can determine the actual digits in a reasonably straightforward manner by successively finding each digit beginning with the most significant one (which is the left most digit).
If Di is the left most digit, meaning that i = N-1, then it there is a value for Di such that
(Di)xBi <= k < (Di+1)xBi
The value that satisfies the above relationship is the correct value for Di. To actually find the value of Di, we could use trial and error (since there are only a limited number of choices available this is not an unreasonable approach).
We could also recognize that the above equation is structurally identical to the one we started with for finding the value of N. Using the left hand inequality and solving for Di, we then get:
Di <= k / Bi
Di = floor( k / Bi )
When we divide k by Bi, we are dividing two integers. Taking the floor of the result is simply taking the integer portion of the result and ignoring (truncating) the rest. This is known as "integer division".
Having found Di for the left most digit, we note that we can now write our number as:
(DN-1)x(BN-1) + DN-2DN-3...D1D0 = k
Where we now have an unknown (N-1) digit number. Solving for this number, we have:
(DN-1)x(BN-1) + DN-2DN-3...D1D0 = k
DN-2DN-3...D1D0 = k - (DN-1)x(BN-1) = k'
We can now repeat the above process to find the left most digit in k' and then keep cycling though this process until we have determined all N digits.
If you haven't already, consider how many digits are required to represent the number zero using our formula. The log (in any base) of zero is undefined, but as we approach zero the log tends towards negative infinity. How can this be? Why doesn't our formula work? The answer is in the very first step we took in setting up our formula when we stated, "where we are assuming that the leading digit is something other than zero." This assumption is compatible for all integers greater than zero, but it is not compatible with the number zero itself. So it is not surprising that it doesn't yield a meaningful result in that special case.
An alternate method that doesn't involve any logarithms and only the simplest multiplication and division operations uses the same concepts and properties used above, but applies them in a more primitive fashion.
Consider the value k = 7635. Ignoring the fact that we can actually see the number because it's printed here, how could we determine that we want to print the digits, from left to right, '7', '6', '3', and '5'?
What if we could first determine that the number is greater than or equal to 1000 but is strictly less than 10000? That implies that 1000 is the weight of the left-most digit. What if we then counted how many times we had to subtract 1000 from the number before we got a result that no longer satisfied this condition (of being greater than or equal to 1000)? How many times would we have to do that? The answer, of course, is seven. Having determined this, we could then print a '7' on the paper and, having subtracted 1000 from the original number 7 times, we would be left with the task of printing out the value 635. The exact same approach would then apply except that we would now be subtracting off increments of 100 (the weight of the new left-most digit) instead of 1000. Each time we move to the next digit, we simply divide the value we are subtracting off by 10 (or, in general, the value of the number base). We continue doing this as long as the weight of the new digit is at greater than or equal to 1.
But how do we initially determine the weight of the left-most digit? We can simply start with the weight of the right-most digit (which is always 1) and see if it is big enough. If it is not, we multiply the weight by ten (or whatever the number base is) and check again. The weight is big enough if the number we are trying to represent is less than ten (or whatever the number base is) times the weight.
The algorithm that comes out of this process is the following:
This is as good a point as any to introduce the notion of "significant digits". A significant digit is one whose presence is critical to the value being represented. Consider the representation of "one dozen". Normally we would write this as:
n = 12
but we could also correctly represent this as:
n = 00000012
Since the presence or absence of the leading zeros does not alter the number being represented, they are considered "insignificant" and we can include them or not depending on what is convenient for our purposes at the time. In general through our discussions in this and later material, when we talk about the number of digits in a number we are referring to the number of significant digits.
While leading zeros (in an integer) are always insignificant, the same may or may not be true for trailing zeros. Given the number:
n = 12000000
The trailing zeros are significant only to the degree that they are a critical part of the value as opposed to simply being required for place keeping purposes within the representation of the value. For instance, if that number represents the exact result of the number of acres in a plot of land, then all of those zeros are significant. If, on the number hand, the number is an estimate of the number of acres that is accurate only to the nearest million acres, then none of the zeros are significant. Something in between these two extremes is also possible where the number might be an estimate to the nearest thousand acres in which case the first three zeros would be significant and the final three would not. Various ways of indicating which digits are and are not significant exist, such as placing an overbar above the nonsignificant zeros, but for our purposes it is sufficient to simply understand the basic concept that trailing zeros might be significant or might only be place holders.
Let's say that we have fourteen gross of pencils (a gross is twelve dozen so fourteen gross is two thousand sixteen) and want to represent this number in base-8.
k = 2016
Let's first determine how many digits there are:
N > ln(2016)/ln(8) = 3.659 (so N=4)
We now want:
D3 = k / B3 = 2016/512 = 3.93 (so D3 = 3)
k' = k - D3 x B3 = 2016 - 3x512 = 480
We can tabulate these results, and the remainder of the results needed to determine all of the digits, in a table such as the following:
k = 2016
B = 8
N < ln(k)/ln(B) = 3.7 (N=4)
| i | k' | Bi | Di = int(k'/Bi) | Di x Bi |
| 3 | 2016 | 512 | 3 | 1536 |
| 2 | 480 | 64 | 7 | 448 |
| 1 | 32 | 8 | 4 | 32 |
| 0 | 0 | 1 | 0 | 0 |
In using the above table, the initial value of i is (N-1) and the initial value of k' is k. The rest of the values in the first row come directly from the first two. In moving to the next row, the value of i is decremented and the new value of k' is the old value (the value from the previous row) less the value in the last column (again, from the previous row). This process is continued until i is equal to zero. The digits of the final number are then easily retrieved from the 4th column. Note that the last value of k' must match the last value in the last column. In other words, k' on the next line (the line with i = -1) should be zero.
The final result is that fourteen gross is 37408.
To verify this result, we can use the properties discussed previously in how to determine the value represented by a number and we get:
k = 3x83 + 7x82 + 4*81 + 0*80
k = 1536 + 448 + 32 + 0 = 2016
Our basic system described thus far only permits us to represent nonnegative quantities. We could, in fact, get along without negative numbers - as countless generations in many civilizations did before us. But negative numbers add a great deal of power to our mathematical tool chest, and therefore we want to be able to represent them in a way that permits us to tap that power.
In every day usage, we simply denote a negative number using a "-" sign in front of the number. But what is a negative number? Most people have long forgotten what the defining property of a negative number is. In short, we invoke the definition of an "additive inverse" whereby the sum of a number and its additive inverse is equal to zero. We refer to the additive inverse of a number as the "negative" of that number. If we look at the implication this has for how a number and its negative counterpart behave under the rules of addition and subtraction, we find a very natural way to represent negative numbers.
Let's say that A is a positive value and we want to find a way to represent quantity B, its negative. By definition, B is the additive inverse of A and hence we have:
A + B = 0
Solving for B, the number we want to represent, we find:
B = 0 - A
By invoking another property of arithmetic, namely the additive identity which states that C + 0 = C, we can write this simply as:
B = -A
So if A is 5, then its negative can be reasonably represented as -5.
It turns out that this representation, while intuitively straightforward and while it actually conveys quite a bit of information to us in a compact fashion, is actually pretty clumsy for performing arithmetic. For instance, consider the steps involved in simply adding and subtracting signed numbers. Our use of a minus sign to represent a negative quantity is so awkward to work with that we simply don't work with it! Instead, we use a fairly complicated set of rules to map it into a problem that can be performed using only positive quantities and then we either keep the final result positive or force it to be negative based upon which rule we invoked to perform the mapping.
As an example, if we have two positive numbers and want to subtract the larger number from the smaller, we invoke a rule that says that we first subtract the smaller number from the larger number (and hence work only with nonnegative quantities) and then, because we noted that we were originally subtracting a larger value from a smaller value and therefore know that the result must be negative, we tack on the negative sign to the result. Take a moment and consider the various rules that you must use to simply add two numbers, either of which may or may not be negative. Pretty complicated - yet we do it without thinking much about it. We can get away with this because the human brain is amazingly powerful at internalizing complicated relationships and algorithms - if they make sense - given sufficient practice and repetition. Consider how we learn to play a musical instrument.
But computers are not good at this type of complicated rule processing - unless some human has sat down and carefully mapped out all of the rules and written very specific instructions for how to implement those rules. We therefore look for a way to represent negative quantities whereby we can perform arithmetic directly on them properly without having to invoke many, if any, special rules. We will hold off on discussing how we actually represent negative quantities in a computer because it involves a bit of sleight-of-hand that relies on a limitation of the range of values that can be represented by a computer - so it makes sense to delay this topic until these limitations are covered and understood.
While being able to represent integers is very important, there are certainly other values that we would like to be able to represent. For instance, how can we use a positional numbering system to represent fractional values such as the result of dividing five into one? First let it be said that we don't absolutely have to be able to do this at all and many cultures throughout history lacked a way of doing it using a positional numbering system. Instead, most of them simply tacked on some kind of fraction at the end of the integer portion to create what we commonly call a "mixed number" and this method is still in widespread everyday use today. It is more convenient for some things but less convenient for other things. By having more than one way to represent something, we gain the ability to use whichever method of representation better matches our needs at the time.
So, having decided that we would like to extend our positional representation so that it can represent fractional values, we look at the structure of our system and discover that a very simple means is staring us right in the eye. Looking at the pattern of what the digits represent, we see that the power to which the base is raised decreases by one until we reach zero for the right-most digit that serves as our units digit. What if we didn't stop there? The next digit would have an exponent of -1, the one to the right of that -2 and so on. Therefore, if we wanted to represent the quantity 5 and 3/4 using our positional system we use the same rules as before and produce the following:
The largest exponent needed is 0 (since 101 is larger than the number to be represented)
The first digit is 5 leaving a remainder of 3/4.
The next grouping size is 10-1 (1/10) and we can extract seven such groups leaving (3/4) - (7/10) = (1/20).
The next grouping size is 10-2 (1/100) and we can extract five such groups leaving nothing.
k = 5 3/4
B = 10
N < ln(5 + 3/4)/ln(10) = 0.76 (N=0)
| i | k' | Bi | Di = int(k'/Bi) | Di x Bi |
| 0 | 5 3/4 | 1 | 5 | 5 |
| -1 | 3/4 | 1/10 | 7 | 7/10 |
| -2 | 1/20 | 1/100 | 5 | 5/100 |
| -3 | 0 | - | - | - |
The resulting string of digits is 575 but immediately we see a problem. How can we distinguish this number from the quantity five hundred seventy five? Or fifty-seven and one-half? Or five hundred seventy-five one-thousandths? We need to know what the exponent actually is for at least one of the digits - after that we can easily determine what it is for any other digit since it increases by one as we move to the left and decreases by one as we move to the right.
We actually had the exact same problem when we were restricted to integers but the solution was so intuitive that we didn't need to explicitly point it out - it was simply understood that the rightmost digit had an exponent of zero. We could solve our problem by merely noting the exponent of either the leftmost digit or the rightmost digit off to the side and, as we shall see in a little bit, this is not so unwieldy as it might seem - in fact we use this method all the time.
But, for everyday quantities, there is a more convenient method. Instead of indicating what the exponent is for one of the two end digits, we simply agree to always do two things - (1) include the digit that has an exponent of zero, and (2) indicate which digit that is. To do the first, we may have to add leading or trailing zeroes to our string that otherwise might not be needed and to do the second we simply place a period to the right of the digit that has a zero exponent. Thus the quantity of five and three-quarters would be written as 5.75 using this convention. We normally call this period a "decimal point" but "deci" implies a base-10 numbering system and this method is equally applicable to any base. The generic term is "radix point".
Thus our expanded system is a very simple extension of our original one and we've really only added a single rule: If a radix point does not exist, then the rightmost digit has an exponent of zero (original rule). If a radix point exists, the digit to the left of it has an exponent of zero.
This method of representing fractional values is sometimes referred to as "fixed point" because the digit to the left of the radix point has a fixed value for the exponent.
Another way of creating a "fixed point" representation is to not place the radix point at all but work under an agreement where everyone knows where it would go if it were there. For instance, if I'm working with the federal budget I might not find it very convenient to have to write down twelve or so digits for each number. Instead, I might simply choose to leave off the last six digits from every number and, as long as I communicate that fact, then anyone reading my data knows that the decimal point is located six places to the right of the last digit shown. Another example is found in the standard format for conveying data for use in automatic machining processes. Here a common format is to present all values as a seven digit number and it is understood that the decimal point is located three places to the left of the last digit.
As stated previously, the fixed point method described above is quite convenient and suitable for most quantities we wish to represent in everyday usage. But it is not too convenient for representing very large quantities or very small quantities since we would have to include a large number of trailing zeroes in the former case and a large number of leading zeros in the latter. Either case is cumbersome and lends itself to making mistakes. So we need another extension.
Recall that previously it was stated that we could simply write the exponent of one of the digits off to the side. That's precisely what we'll do. Our new rule will be that we can take a fixed-point number and make what would normally be the units digit (the digit to the left of the radix point or, lacking a radix point, the rightmost digit) and assign it an exponent of our choosing. To indicate what that exponent is, we merely write it off to the side - normally the right-hand side. In order to avoid confusing this second number, called the "exponent", with the base number we started with, known as the "mantissa", we separate the two with a space or some other "delimiter". The most commonly used delimiter is the character 'e' (for "exponent") but another common convention is to always include the sign of the exponent and make that character perform double duty by acting as the delimiter as well.
This notation is generally referred to as "exponential notation". Another name for it is "floating point" because the radix is no longer at a fixed location relative to the digit with a zero exponent. It is allowed to "float" and we simply keep track of where it has floated to.
Thus, a number like 123.45e5 means that the digit '3' actually has an exponent of five. The rest of the rules are unchanged and hence the digit '2' has an exponent of six and the digit '4' has an exponent of four.
There are a few ways of interpreting this notation. There is, of course, the way it was just described where the integer to the right of the 'e' is the exponent of the digit to the left of the radix point. This comes directly from our definition of this representation.
This representation is also commonly referred to as "scientific notation" but that is a bit of a misnomer. In scientific notation, the number is factored into two parts such that one of the factors is an integral power of the base. The power is chosen so that the other factor can be conveniently represented using the previously developed fixed-point radix notation.
So our number above could have been written as 123.45x105 in scientific notation. For completeness, we'll point out that in scientific notation the power is generally chosen so that the mantissa is "normalized" meaning that there is exactly one digit to the left of the radix point. Hence, in this example, the normalized representation would be 1.2345x107. In an alternative known as "engineering notation" the power is chosen so that it is a multiple of three which makes the use of scaling prefixes such as "milli" and "mega" more convenient. Our example might be expressed in engineering notation as 12.345x106.
Now, on the surface, it looks like the only difference between "scientific notation" and "exponential notation" is one of semantics. The "x10" is replaced by "e" and the exponent isn't written as a superscript. This slight change of notation allows us to type the numbers into a text file without needing any special characters for the exponent. So why do we claim that equating "exponential notation" and "scientific notation" is technically not correct? Because this similarity and ease of mapping is not intrinsic to the two representations - it is the result of a very deliberately chosen convention.
To see what is meant by this let's, for the moment, assume that we had chosen a different convention for our exponential notation. Let's specify that the mantissa would always be written as an integer and the number to the right of the delimiter is the exponent of the leftmost digit. In that case, the number we have been working with above would have been written as 12345e7. This convention actually has some advantages over the accepted convention, such as making it very easy to order a list of numbers. Had this, or another, convention been adopted we would have gotten used to it and learned how to convert between exponential and scientific notation just as we have learned how to convert between fixed-point and scientific notation. But, just as mistakes are commonly made in translating between fixed-point and scientific notations, it would have been common to see mistakes made when translating between exponential and scientific. The people that developed the accepted convention for exponential notation recognized that having the exponential notation be equivalent to scientific notation for all practical purposes would minimize these translation errors and that this constituted a much stronger advantage than any of the other conventions might have had.
The purpose of this digression is twofold:
First, it points out the distinction between the "definition" of something and the "properties" of that same thing. The definition is what actually establishes what the thing is. It is generally expressed in the shortest, clearest terms possible. The "properties" of something are merely consequences of the definition, but the properties do not define it. In our case, a working definition of the exponential notation could be as simple as: Take a fixed point number and move the radix point to any convenient location within the number. Then append a delimiting character and the exponent of the digit to the immediate left of the radix point. Given this specific definition, our exponential representation has some interesting and useful properties - properties that it would not have if the definition has been different. For instance, because the digit to the left of the radix point would normally have had an exponent of zero, there are a couple of other interpretations that become useful. One is to think of the value to the right of the 'e' as the value that is added to the normal values of all of the exponents in the original fixed-point value. In the number above, 123.45e5, the digit '1' normally would have an exponent of two, so five is added to this, and it now has an exponent of seven. Likewise, the '5' would normally have an exponent of negative two and therefore now has an exponent of positive three. Another very useful way of thinking about the representation is that the mantissa is multiplied by the number base raised to the indicated exponent. In the number above, this means that we have 123.45x105 and hence the intentional behavior that exponential notation maps very easily to scientific notation.
Second, it emphasizes that there is nothing rigid about number representation. If we decide that we would be better off using a different definition for the exponential notation, then we are completely free to do so. Keep in mind that if we ever need to communicate values to someone else, we will either have to go to the effort of making it clear that they understand how to interpret our representation or we will have to convert to one of the commonly accepted representations. But if we only intend to use our custom representation for internal computations, then by all means we can feel free to develop a representation that best suits our needs - we just need to be consistent in its use. In developing a custom representation, it is very useful to keep in mind the difference between the "definition" and the "properties" of our representation. Doing so will make it much easier to ensure that our representation is adequately defined and that we use it consistently.
Following up further on the closing remarks of the previous section, hopefully you have noticed a strong thread running throughout this discussion. When representing numbers, there is nothing mystical or magical about them and there are several representations we use in normal everyday life. The reason why more than one exists is because no single representation is perfectly suited for all numbers or, more importantly, for all applications involving those numbers. So we have developed a handful of representations and we choose the one that is best suited to our needs at the time.
Furthermore, it is not uncommon at all to switch back and forth between different representations in the process of performing a given task. For instance, in constructing a roof truss we might write the measurements taken with a tape measure in mixed notation using fractional inches, add a few of them together this way, then convert them to decimal inches to plug them into some formulas, and then convert them back to mixed notation when it comes time to lay out the resulting lines on the lumber to be cut.
Two lessons should be drawn from this:
First, working with different representations and converting between them is something we do all the time, but it is not natural to us. We learned how to do it and spent a considerable amount of time, effort, and practice to develop the necessary skills. For similar reasons, we will find that having a few different methods of representing numbers within a computer is very convenient and that we will need to be able to convert back and forth between them. It should therefore not come as a surprise that becoming conversant with how to do these conversions will require some time, effort, and practice.
Second, how a number is represented should be driven by the number itself combined with how that number is going to be used. It should not be driven solely by a reluctance to choose a proper representation from among the many that are available. Furthermore, we should not even restrict ourselves to just the ones that are available. Remember that we have more than one because no single one is perfectly suited to every occasion. The same is true for the collection of representations as a whole. They are highly flexible, but it is expecting too much to insist that one of them is perfectly suited to every occasion. If your needs argue for using a custom notation, then use a custom notation. You just need to be sure that your notation is up to the task at hand and that you use it consistently.
A lot of information has been presented in this module. As much as possible, the viewpoint used in presenting the material was from a problem solving approach. Without this understanding, you would be relegated to using rote memorization - a tactic that quickly becomes counterproductive in the field of engineering. Even more importantly, for the purposes of this course, such a presentation would have conveyed little about the steps used in solving engineering problems.
The author would like to acknowledge the following individual(s) for their contributions to this module: