(Last Mod: 27 November 2010 21:38:38 )
If we were to examine the instructions actually contained in a programs executable code, we would find a long list of instructions. Normally, those instructions are executed one after another in the order they appear in the program file. A few instructions, however, have the ability to control the flow of the program. In practice, this simply means that they have the ability to make some instruction other than the one that immediately follows it the next instruction. These flow control instructions, known as "branch" or "jump" instructions come in two varieties - conditional and unconditional. Unconditional jump instructions always transfer control to a specific point in the program. Conditional branch instructions, however, may or may not transfer control depending upon some condition that can be tested. These conditional branch instructions are the true power of any program - without them very few truly useful programs could be written or executed.
But, as powerful as they are and despite the fact that any program we write eventually must be translated into a set of executable instructions composed of these instructions, such a program is extremely difficult for humans to comprehend. Not impossible, but very difficult. Anything beyond the shortest of programs quickly overwhelms a programmer's ability to keep track of what is happening and to ensure that the program is going to behave as intended. So we develop ways of imposing the appearance of structure to the code as we see it. In a low level programming language, such as assembly language, this is based primarily on how we group our instructions and how we document our code. It takes a great deal of discipline to maintain a suitable level of structure and organization when working at such a level. High level language, on the other hand, were primarily developed for the purpose of letting us write code in a highly structured way using constructs that are easy for humans to comprehend. We rely on compilers and interpreters to translate our structured programs into the highly unstructured world of the machine code.
Structured programs use Code Blocks that perform well defined tasks as the basic building blocks of our program. Any time we execute a Code Block, we execute the entire block before doing anything else. Once we are done, we execute some other block in the same fashion. Which block we execute depends on what type of flow control we are using. There are three types of flow control that we can use - sequences, selections, and repetitions.
Sequence flow control means that the next block to be executed is always the same block. For instance, after executing Block #34, always execute Block #48.
Selection flow control means that, after completing the current block, we evaluate some kind of logical test expression and execute one of two blocks depending on the outcome. For instance, after executing Block #21, execute Block #63 if the number we are working with is negative otherwise execute Block #85.
Repetition flow control is really just a special case of selection flow control where one of the options after completing the current block is to execute the current block again (from the beginning, of course, since it only has a single entry point). For instance, after executing Block #55, execute Block #55 again if the exponent is greater than zero, otherwise execute Block #72.
By adhering to a structured programming paradigm, the programs we write are much better organized, quicker to develop, easier to test and verify, and much easier to modify and maintain. There are few, if any, programming tasks that cannot be implemented using structured programming. That is not to say that a structured program might not be less efficient that an unstructured one that performs that same tasks, but in most cases the performance penalty, even if rather extreme, is well worth the benefits that structured programming provides. But, certainly, there are times when the need for performance argues persuasively against adhering to a structured approach in favor of a more computationally efficient unstructured one - which is why assembly language still is and will continue to be an important tool at the programmer's disposal.
Flowcharts are nothing more than a graphical way of representing a program or algorithm that - it turns out - lend themselves particularly well to structured programming. Please review the material on flowcharts for a detailed discussion of what they are and how they work.
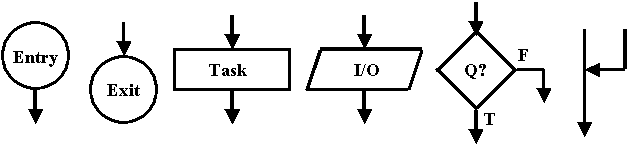
In the very simple flowcharts we will be dealing with, we represent the entry and exit points with circles, blocks of code with rectangles and parallelograms, decision points where we decide which block to execute next with diamonds, and we tie these elements together with arrows to show the order that blocks are executed in.
In a structured flowchart, we always only have one entry point with a single arrow leaving it. That arrow either goes to a Code Block, or it goes to a decision point. Technically, it could also go to the exit point, but that makes the algorithm being represented rather trivial. Having said that, it is actually not too uncommon to do precisely that when developing code. We may temporarily implement some parts of the algorithm using using a block of code that does absolutely nothing expect compile and run and do absolutely nothing in the process. Doing something like this allows us to get a program running so that we can focus on other parts of the program and come back to this one in good time.
In a structured flowchart, we would ideally have a single exit circle. Any point in our algorithm that wanted to exit the block being represented would proceed to the exit circle. In practice, adopting that approach can lead to unnecessarily busy flowcharts so, instead, we permit multiple exit circles with the understanding that they are really all the same one and that whenever we reach one we exit the block and always proceed to the same point at the next higher level regardless of which exit circle we actually came to.
This has a direct analog in how we actually write our functions in C - we might have many different return statements in a function (though some effort should be made to minimize them if practical) but all have exactly the same effect. They exit the function and return program control to the same point in some other function from it was called.
When writing structured programs, we write our code so that it consists of blocks or modules that perform some task. That task may be at a very low level - printing a single character to the screen or taking the square root of a number - or it may be at a very high level - opening a windows bitmap file, converting it to a jpeg image, and writing the new image out to a new jpeg file.
What characterizes a block of code, from the perspective of structured programming, is that it have a single entry and a single exit point. As long as we adhere to this rule, we can treat our block of code as a black box that performs some task and, just as importantly, when we are working with the code inside the block we don't have to be excessively concerned with what happened before the block was called or what will happen after the block is finished.
By a "single entry point" we mean that anytime we enter a block of code we always do so at the same point. We never jump into the middle of a block of code. If the first thing that the code within the block wants to do is jump around to some other point within the block, that's fine. As long as the first statement that gets executed is the same, we are covered.
Similarly, "one exit point" means that, when our block of code has finished running, it always transfers control to the same point. We might have many return statements within a C function, but each one of them returns program control to the same point - namely the point that the function was called from.
Blocks that adhere to the single-entry/single-exit philosophy are much easier to develop, modify, and maintain that blocks that do not. Functions in C obey this principle by the very nature of how C functions work. But the code we write within a function can also be written using this philosophy - or not. That's up to us. If we choose not to, then we deprive ourselves of the benefits of structured programming which is not something we should do without an extremely good reason.
A flow arrow simply shows us which block gets executed next. An arrow has a head and it has a tail. Flow always proceeds toward the head of the arrow. A block has exactly one flow arrow pointing to it and one flow arrow leaving it. Flow arrows can converge, but they can never diverge. If they converge, it simply means that more than one path leads to a given block For instance, we might have an arrow telling us to execute Block #17 after finishing Block #10. But that does not preclude us from wanting to execute Block #17 after finishing Block #26, too. Since we don't want two arrows ending at Block #17, we make one of the arrows point to the middle of the other arrow. If the head of one flow arrow points to some point on another arrow, flow continues along the direction of the other arrow.
The reason that arrows can't diverge is because we would need some way to know which path to follow. But being able to have paths split and our program select from among the possible paths is at the very core of computer programming. To accomplish this, we use a decision point. At it's most basic level, a decision point has one arrow leading to it and two arrows leaving it. Some for of test is associated with the decision point and, based on the result of that test, we either leave the decision point along one path or the other.
The decision point described above might be called a "one-of-two" decision point. Decision points can also take a "one-of-N" form having N paths leading from it. Which path is taken is still determined by some test condition associated with the decision point. This type of structure is really just a shorthand expression for a more complicated diagram having many one-of-two decision points. In C, this type of decision point is well suited for the switch() selection construct.
Sequences are simply chains of Code Blocks that have no decision points between them. They are always executed in the same order every time. In C, sequences are generally implemented as nothing more than a series of statements listed one after another.
Selections (and repetitions) occur at decision points in the flow chart. The distinction between a selection and a repetition is conceptual only. In general, if neither of the paths leaving the decision point can lead back to the same decision point or, alternatively, if they both can, then it is a selection point. If one of the paths leaving the decision point eventually comes back through the same path leading up to it and the other path does not, it is a repetition point. In C, selections are implemented using an if(), if()/else, or switch() construct.
Repetitions (and selections) occur at decision points in the flow chart. The distinction between a selection and a repetition is conceptual only. In general, if one of the paths leaving the decision point eventually comes back through the same path leading up to it and the other path does not, it is a repetition point. If neither of the paths leaving the decision point can lead back to the same decision point or, alternatively, if they both can, then it is a selection point. In C, repetitions are implemented using a while(), for(), or a do/while() construct.